Using gedit, snippets and regular expressions
Introduction
What this tutorial is about, and what it isn't
There are various workflows which people on MIA use to do HTML markup and correct OCR errors, and this is just one of them. No implication is made here that this is the best one. People should use those tools that they know how to use and are comfortable with. However, the claim is made that these particular methods clearly beat copy-pasting repeating sections of code, not to mention typing such code by hand! Hopefully this tutorial will contribute something towards MIA volunteers' ability to make informed choices about available options when they're choosing between various tools for their work.
The tools that are recommended here for this purpose are gedit and sed. gedit is a text editor with useful functionalities for HTML markup, and sed is a command line tool can be used to automate the clean-up of OCR program output. Both of them are available for Linux, Windows and Mac. This tutorial will help you use gedit's snippets functionality and describes with some examples and in outline how to use regular expressions (regex) to search and replace text with both gedit and sed.
Please note that page is not intended as a comprehensive tutorial on either program. The idea is just to point out two features that are helpful in doing HTML markup, and the demonstration of these two features is done by showing concretely how it's done with two particular programs.
If you'd like to use these features but don't want to switch away from your favourite editor, or can't use gedit or sed for some other reason, you could just check whether in fact your current editor happens to support snippets and regular expressions as well. Snippet functionality and regex search-and-replace are likely to be found in editors geared towards programming. Just make a web search on your editor's name together with "snippets" or "regular expressions" and see if anything turns up.
Installing gedit
gedit can be downloaded here for all operating systems. gedit is the default editor for Gnome (Linux), and if you're not using Gnome on your particular Linux distribution, it is likely that it's available in the repository (check the Software center or its equivalent).
Once you've downloaded and installed gedit, let's setup the 'Snippets' plugin. From the menus, find 'Preferences' and then a tab named 'Plugins'. 'Snippets' is included in the default plugins, you just need to activate it by checking the box next to it. After activation, you now have a new entry in the menu (either the all-in-one menu or in the Tools menu) called 'Manage snippets'.
The second feature that is covered in this tutorial is regular expressions (more on that below), which also is available in gedit by default. When you hit Alt-H for the search and replace function, you see a box in the search and replace window that pops up, saying 'Regular expression'. Check the box if you want your search and replacement phrases to be interpreted as regular expressions, and leave it empty if you want them to be taken "literally", i.e. as in normal search and replace.
One final thing before we start with snippets and regex: gedit recognises the type of file (plain text, HTML etc.) you're editing, and highlights the code parts of the text with various colours, so that it's more obvious at a glance which parts are code and which are normal text. This helps a lot when trying to look for missing tags for example. You can also select manually the type of file you're editing from either the View menu ('Highlight mode...') or from the bottom bar of the editor window, where the current file tyle is given ('Plain text', 'HTML' etc.)
Using snippets
What are snippets?
Snippets are chunks of pre-written text that can be used in (for example) doing HTML markup to save you the trouble of having to write repeating bits of markup by hand (or manually copy-pasting them). Snippets can be short, like for inserting a footnote, or long, spanning dozens and dozens of lines, like for inserting a whole template for a particular type of job.
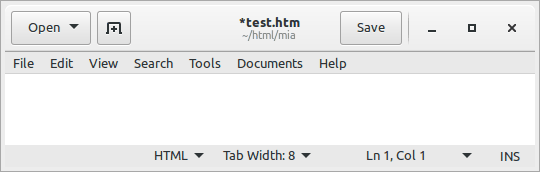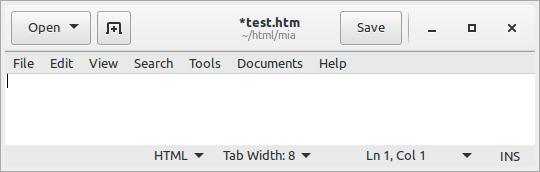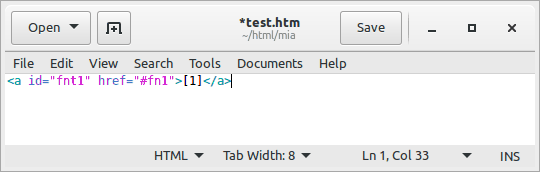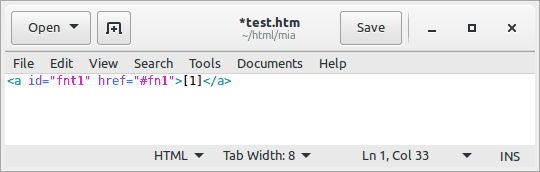
First, you need to decide which bits of markup you need to have as snippets — in practice they're the ones that you'd have to write repeatedly. So let's take the markup for a footnote that you insert into the main body of the text. The markup might be something like this: <a href="#fn1">[1]</a>. You'd include this bit of code into your snippets database. Second, you'd decide a trigger phrase for it. Let's say "fn" is the trigger phrase. Now, when you're editing a text, you write "fn" (which will appear on the screen just like any text you type) followed by a press on the tabulator key (<Tab>), which now inserts the snippet defined for that trigger phrase into the text, replacing the "fn" that you just wrote before pressing <Tab>.
See the GIF animation to the right of how snippets work in practice. You write the trigger phrase, press <Tab>, and the trigger phrase is replaced by the snippet text.
Making your own snippets
If you've activated the 'Snippets' plugin as advised above, select 'Manage snippets' from the all-in-one menu or the Tools menu, depending on your editor version.
In the 'Manage snippets' window there are three sections. On the left hand column there is a section with lots of programming languages listed; the upper part of the right hand column is an editor window where the contents of the selected snippet appears, and where you can insert your own; and the lower part of the right hand column contains boxes for the trigger phrase, an optional shortcut key, and 'Drop targets', the last of which won't be covered in this tutorial.
Concerning the left hand column, for MIA purposes we are interested in two submenus there: 'Global' and 'HTML' ('Global' is the very first menu on the list, the rest are in alphabetical order). This setup allows for making customised snippets for particular types of files, including HTML files; snippets in the 'Global' menu will apply to all edited files, regardless of their kind. gedit will recognise which kind of file you're editing, and choose the matching snippets. Snippets defined for .txt files will not work when editing .html files and vice versa; if you want to use some snippet with two file types, you need to include them in the snippet lists of both file types, or put it in global snippets.
We're mostly interested in HTML snippets though. So scroll down to find the HTML snippet submenu in the list and open it. You will now see all the available snippets for HTML files. There's plenty of defaults there, which cannot be deleted, though they can be edited to your liking. The titles for each snippet list two things: first, the name of the snippet, and in parentheses in bold text, the trigger phrase.
Let's make a test snippet. After having selected the HTML menu or any of the snippets it contains, click on the 'Plus' button at the bottom of the column to create a new snippet called 'New snippet'. Change it to "MIA test snippet" (it makes sense to put "MIA" or something similar in the name, so that you can immediately distinguish between default and user snippets), and then click on the upper part of the right hand column. Enter whatever you like there, e.g. "This is a test snippet". Next, in the lower part of the right hand column, select the 'Tab trigger' box and type some trigger phrase for the snippet. It makes sense to use something you can remember easily but something that's not likely to be a real word, in case you want to use the tab key for inserting actual tabs. So let's choose "tst" for the trigger phrase.
Finally, you can select the 'Shortcut key' box if you like. Once you've selected the box, you will be asked to press a key combination (i.e. not type it, but press simultaneously the 2-3 keys you want) to assign it for this particular snippet. You can use a Ctrl, Alt or their combination with a letter or number. Let's press Ctrl and 1 simultaneously to insert a shortcut key combination.
Defining the shortcut key is optional. A shortcut key is not necessary, and in fact it probably makes sense to have shortcut keys for only the most common snippets, as there is a limited number of key combinations available (note that some key combinations might be in use by the editor itself, like Ctrl-S, or the desktop environment of your computer, like Ctrl-Alt-Delete), and it might be hard to remember two dozen combinations anyway, especially if they don't get frequent use.
Now you can proceed to test the new snippet. Close the 'Manage snippets' window and make sure that the file you're editing has been saved as an .htm or .html file. Type tst and hit <Tab>. The text of the snippet should appear, replacing the "tst" that you wrote. Next, press Ctrl+1 or whatever shortcut you chose to insert the snippet for a second time.
The next step is to think about all the possible snippets that you might need. Some obvious candidates include: footnotes inserted into the body of the text, HTML templates for different purposes (e.g. for the most common authors whose writings you work on), inserting 10 footnotes at the bottom (separate snippets for footnotes 1-10, 11-20, 21-30 .. 190-200 etc. — and separate series of them for both editor's and author's footnotes), inserting a empty line (<p class="skip"> </p>), table of contents, templates for various types of ordered and unordered lists, etc. etc.
Snippets with placeholders
An advanced type of snippet is one with placeholders. What this means is best demonstrated with an example. Let's continue with the footnote snippet example. HTML markup for footnotes typically contains the same ordinal number in several locations in the snippet. You can use placeholders to denote the places where something needs to be inserted, and then copy that number automatically to other locations in the snippet. The snippet placeholder syntax is as follows (the placeholder demanding an input in dark red, the locations where the input is copied to in dark green):
<a id="fnt${1}" href="#fn$1">[$1]</a>
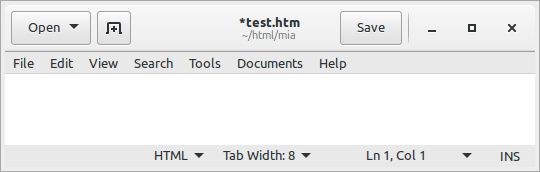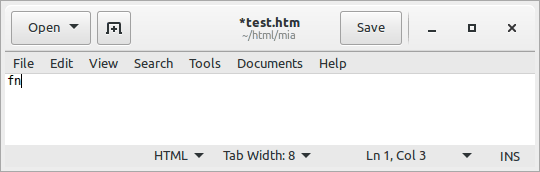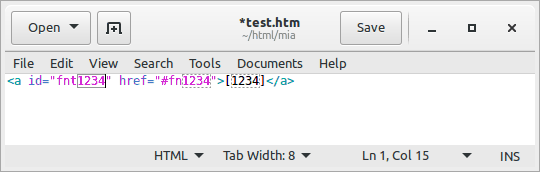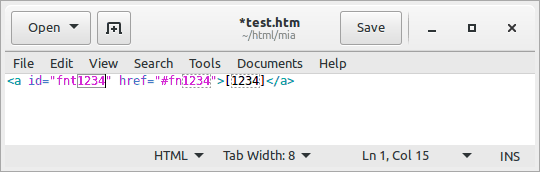
See the GIF animation to the right on how placeholders work in practice. First you type the trigger phrase, then press <Tab>, then enter the numbers. The numbers are copied to the location(s) you have defined in the snippet as you type.
You can denote multiple placeholders with ${x}, where x is a number. This placeholder (one with curly braces) expects an input. If the same input needs to be copied to several locations in the snippet, you can effect that with $x (i.e. without the curly braces; see the example above). If you have multiple placeholders in the snippet that expect an input (${1}, ${2}, ${3} etc.), you can jump to the next one with <Tab>. This saves you from having to move the cursor by arrow keys or by mouse to the next location that needs an input.
A placeholder can also have a default value: ${1:default value here}. Starting to type deletes the default value and inserts what you type, while pressing <Tab> inserts the default value and jumps to the next placeholder (or the end of the snippet, if there are no more placeholders).
Search and replace with regular expressions
Regular expressions (or regex) is a complex tool that requires some study and experimentation to get it right. The notation is abstract and doesn't make intuitive sense, so some things just have to be memorised in the beginning. In that sense it is like a new language whose logic doesn't make sense initially and you just have to accept that this is how it works, whether you fully understand it or not. What complicates matters is the fact that there are several "dialects" of regular expressions, meaning that while different programs might understand regex in principle, they interpret the notation a bit differently. If you're not aware of the particular "dialect" of regular expressions of the program you're using, you might end up replacing text that you didn't intend to replace, or then your search and replacement phrases just don't work. Especially with sed this can be dangerous, because unless told otherwise, sed will just save any changes it made in the file without asking. That's why you should experiment with a "practice version" of the file you're editing with sed, and check that the changes really are what you intended, and only then perform the changes on the actual file you want to edit. In gedit you at least have 'undo', but with sed you need a backup copy.
This section covers two uses of regular expressions: search and replace within gedit, and search and replace using the command line tool 'sed'. As it happens, these two programs unfortunately speak different dialects of regex. The extent to which this difference becomes evident in the context of this tutorial is not that great, but it is there (see the appendix for details).
Also it should be repeated here that this tutorial doesn't aim to be a comprehensive tutorial on regex — far from it: it will only show some of the most obvious uses of regex for MIA transcribing and HTML markup purposes. The intention is to give some idea what regular expressions are and how you can use them in practice, to try to describe the logic of operation and to show that it's humanly possible to understand that logic, and encourage you to study further so that you can replace tedious and time-consuming manual editing with a few regex commands.
Search and replace in gedit
Important note! The following examples work with the particular regex "dialect" gedit uses! Other editors and programs might use a slightly different dialect, and the examples below might not work without slight changes! (See the appendix for some differences between gedit and sed regex.)
The typical search-and-replace function of a word processor or simple text editor recognises only exact matches, with perhaps a possibility to discriminate between upper and lower case letters, but that's about it. With regular expressions you can search-and-replace text much more refinedly and intelligently. Say you want to change the markup of all the footnotes in your completed text. They're all the same, so normal search-and-replace might work... except for the ordinal number, which is different for each footnote. For simple search-and-replace, each footnote is different because there's one rogue character there that is different.
However, with regular expressions you can get around this.
Let's say your footnotes appear in the text as numbers inside square brackets[1], and you'd like to give them a CSS class (which they don't have at the moment) as well as make them into upper indexes.[1]
You'd search for:
<a id="fnt([0-9][0-9]*)" href="#fn([0-9][0-9]*)">\[([0-9][0-9]*)\]</a>
and replace it with (for example):
<sup>[<a class="fn" id="fnt\1" href="#fn\2">\3</a>]</sup>
What does the notation mean? In the search phrase, there's several occurrences of [0-9][0-9]* between ( ). The former expression means, "at this point in the search, look for one or more numbers", and the latter expression means, "save what you found in between ( ) into slot X" (where X is the ordinal number of the "save what you found" in the phrase, so that the first occasion of "save what you found" in the phrase is saved into slot 1, the second occurrence into slot 2 etc. The numbers are determined by the order of the saved expressions in the phrase, so you don't need to number them explicitly.)
The third occurrence, the one where you search for a number between square brackets, needs some extra backslashes (\), because with regular expression the square bracket is a special character. If you put simple square brackets around something, it will be interpreted as "look for any of these characters inside the square brackets". Thus, searching for [word] means "look for any of the letters w, o, r, d",[1] while searching for \[word\] means "look for the word 'word' inside square brackets".
So, if you want search for a plain square bracket, instead of using it as a "meta character", you need to "escape" it with a backslash: \[. So just a [ is a special character, but \[ is a normal square bracket, just like any other character that you're looking for.
The same applies with other special characters too, for example the parentheses ( and ). Searching for \(word\) means "search for the word 'word' inside parentheses", but searching for (word) means "search for the word 'word' and save it into slot X" (a valid but a bit of a nonsensical command, as normally you'd want to save only something that you don't know in advance, i.e. typically something with wildcard characters).
One final note. To look for "one or more numbers", you use the notation, [0-9][0-9]*. What does this mean? If you searched for [0-9]*, it would mean, "look for zero or more numbers". This logic is something that should be given some thought. Zero or more. If the program finds an a, or anything at all for that matter, that is "zero or more numbers"; there is zero numbers in an a, after all. So what you want to do in practice is always use [0-9][0-9]* to find "one or more numbers", or [A-Z][A-Z]* to find "one or more of any uppercase letters".[2]
Search and replace using sed
Important note! gedit and sed use a different dialect of regex! Do not cross-reference examples from the gedit sections for sed use and vice versa! (See the appendix for some differences between gedit and sed regex.)
sed is a command line tool for editing text. If you're on Linux or Mac, you already have sed installed. If you're on Windows, you will have to download the GnuWin32 sed package here and install it. (Likely you will have to add the program's directory to your system path and become familiar with the Windows Command prompt tool.)
Using regular expressions with sed works more or less (a dangerously vague expression, the details of which we'll look at in a minute!) the same as with search-and-replace in gedit, though with sed it's more convenient to make mass search-and-replace on a file before you start editing it by hand and making those snippets fly. A useful case is stripping the output .html file of an OCR program from all the unnecessary HTML markup and replacing it with standard MIA markup, so that you just have the proof reading and markup fine tuning left to do. The way to do this is writing your several dozen individual search-and-replace commands into a script file (a "script" here means simply a list of automated commands), which can then be run on an .html file with a single command:
sed -f ~/path/to/script/sed-script-file.txt dirty-target.html > clean-output.html
NB!! Unless told otherwise, sed will write any changes in the target file without asking and before you get to see them, and there is no 'undo'! This means you should have a backup copy of the original file to protect against unwanted edit accidents, unless you're really sure of what you're doing. (And anyway you will seldom find yourself thinking, 'why oh why did I make that backup copy', so having backups is just normal good practice.) The command above has sed works around this feature by having it write the changes into another file (here named "clean-output.html"), however the point here is that the program needs to be told this explicitly.
What you want to include in your sed script file depends on your OCR program's output and what you want cleaned and what retained. "One size fits all" solutions don't exist, and you'll have to understand how regular expressions work in order to apply them to your particular case. Alternate between reading a good guide on regular expressions (see the Further reading section below) and making experiments on test files to see how each command changes the text and what the logic is. It will not be easy if you start from zero, but hopefully you will begin to see the logic eventually. All that is offered here is some practical examples that work for the HTML output of ABBYY Finereader, and their explanations.
All the sed commands in this tutorial are of the kind,
s|look-for-this|replace-with-this|g
meaning "look for this phrase and replace it with this other phrase everywhere in the target file". The "s" in the beginning tells sed to "substitute", and the "g" at the end means, "globally", i.e. everywhere in the file, instead of just the first occurrence on every row. (sed works on a row by row basis, so that each command is applied to one row at a time). The three |'s separate different parts of the command from each other. The separator need not be |, in principle it could be anything, but it's useful to use some character that is not in either the search phrase or the replacement phrase. Other good candidates are / (forward slash) and ! (exclamation mark).
For easier reading, the search phrase part of the command is coloured dark red and the replacement phrase part is coloured dark green. Special expressions (i.e. ones that are not for looking for "literal" matches of the characters in question) are coloured with pink and lime green, respectively.
Here is a section of a sed script file:
# keep all italics, whether of the font or span variety
s|<span[^>][^>]*italic[^>][^>]*>|<em>|g
s|<font[^>][^>]*italic[^>][^>]*>|<em>|g
s|<em>\([^<][^<]*\)</font>|<em>\1</em>|g[3]
s|<em>\([^<][^<]*\)</span>|<em>\1</em>|g
# remove all other font and span styles
s|<font[^>][^>]*>||g
s|</font>||g
s|<span[^>][^>]*>||g
s|</span>||g
What this section does is it removes all styles except for italics from the ABBYY Finereader HTML output file (the replacement phrase in the latter four is an empty nothing, i.e. if something is found, it's simply deleted). Let's break it down line by line. (The starting "s" and ending "g" were already explained above, so only the search and replace phrases are explained below.) First, the whole phrase:
s|<span[^>][^>]*italic[^>][^>]*>|<em>|g
The search phrase part is:
<span[^>][^>]*italic[^>][^>]*>
In plain language (more or less!), this looks for: "the characters <span, followed by anything except for one or more >, followed by the letters italic, followed by anything except for one or more >, followed by a >.
To break the phrase down:
1. Look for the characters '<span' (in this particular order): <span
2. Look for anything except one or more closing angle brackets: [^>][^>]*
3. Look for the characters 'italic': italic
4. Look for anything except one or more closing angle brackets: [^>][^>]*
5. Look for exactly one closing angle bracket: >
If any of these conditions fails, the search phrase is not found. And it's even stricter than that: in order to proceed from one part to the next, the preceding part must have found a match first. Thus, if a line doesn't contain the phrase part <span, the search will not find italic either, even if it occurred several times on the row in question. The phrase part <span must be found first.
Keeping this in mind, let's consider how this command works with two example phrases, one of which we want to find, and one very close to the one which we want to find, but nevertheless one which we don't want to find:
<span style="whatever;font-weight:italic"> (this is what we want to find and replace)
<span style="whatever;font-weight:normal"> (this is what we don't want to find and replace)
Let's see what the logic in each of the sections is, and then how each of the conditions is met (or not).
1. Looking for the characters <span is clear. Sed will look for exactly these five characters in this particular order, and nothing else. Both our example phrases match this condition.
2. Looking for anything except one or more >. There's plenty of characters that are not > in both phrases after the first part was matched , so both of the example phrases match this condition.
3. Look for the characters 'italic'. This matches our first example phrase, the one we want to find, but not the second one, because even though the two preceding conditions were met, this one isn't: the word 'italic' is not in the phrase. But let's consider another possibility of a phrase that is very close to the one we want to find, but one which we don't want to find:
<span style="whatever">italic</span>
If the actual text between the <span></span> tags contained the word 'italic', that would be actual content, not rubbish HTML markup that we want to get rid of. However, it would not be found, because before finding italics the order was to find "anything except for one or more >". And if you look at the phrase immediately above, there is a closing angle bracket > there just before the word italic. This is the reason why we want to find "anything except for >". (Here we rely on ABBYY Finereader producing consistent HTML.)
4. Look for anything except one or more >. So we know our second example phrase has already failed to be found, because one of the conditions has not been met. But concerning the first one, we still want to match everything that is inside of the opening <span> tag in order to replace the whole tag with another tag, <em> (the opening "emphasis" tag). So after finding italic, we look for "anything except one or more >"; after all, italic probably isn't the last style definition inside the opening <span> tag, so we need to match all of that as well. Finding anything except > does the trick.
5. Look for exactly one >. We still need to find the closing angle bracket for the opening <span> tag, and if it's found, we have a match.
To recap: The first example phrase, the one that we wanted to find, was found because we found the word italic inside the opening <span> tag, along with anything else except for a closing angle bracket >. The closing angle bracket was then found as a separate search condition (the 5th condition). The second example phrase, the one we didn't want to find, was not found, because there was no word italic inside the opening <span> tag. And neither did we find the other phrase that was very close to our looked-for phrase, because in the second unwanted phrase the word italic was not inside the opening <span> tag, but instead is was between the opening and the closing <span></span> tags (i.e. it was defined by the tags, instead of defining what's inside the tags).
So, back to the commands in the sed script file. The second command in it is exactly the same as this one, only that instead of <span it looks for <font. This is for completion's sake, and doesn't hurt if it's not found. But if it is: the <font></font> tag is deprecated and it's not recommended for use in HTML markup any more, so all the more reason to get rid of it!
The first command's search phrase was much more complicated than the replacement phrase. If there is a match, it is simply replaced by an opening <em> tag, and that's it.
The next line in the script file is:
s|<em>\([^<][^<]*\)</span>|<em>\1</em>|g
With the first command we replaced all italics defined with <span> tags with a simple <em> tag. Now we want to replace all closing tags for the italics <span> tags with a closing </em> tag to complete the tag definition. To do that, we need to find the opening <em> tag, then everything between that and the closing </span> tag that remains, then save what we found between the <em></span> tags, then replace the closing </span> tag with a closing </em> tag, and finally insert what we saved in between the <em></em> tags.
Again, let's break the command down to bits:
1. Look for the characters <em>, in this particular order.
2. Look for anything except for one or more opening angle brackets and save whatever was found: \([^<][^<]*\)</span>
3. Look for the characters </span>, in this particular order
Let's see what the logic in each of the sections is, and then how each of the conditions is met (or not).
1. Looking for an opening <em> tag. This one is pretty clear.
2. Looking for anything except an opening angle bracket <. This matches everything that's in between the opening <em> tag and whatever the next closing tag will be. Because we trust that ABBYY Finereader will open and close tags always in the proper order (i.e. close the last opened tag first), the first closing tag after the opening <em> tag will be its counterpart.
3. Looking for the characters </span>, i.e. find the closing tag. Pretty clear.
In contrast to the replacement phrase in the first command, the second command's replacement phrase is a bit more complicated and requires some explanation. The phrase is:
<em>\1</em>
We wanted to find <em>, followed by anything except for an opening angle bracket < (and that anything was saved), followed by </span>. We want to replace it with:
<em>whatever-was-found-and-saved-is-inserted-here</em>
The opening and closing tags are kind of plain language, but the saved part needs an explanation. If you recall, in sed we can save what is found by surrounding the looked-for phrase with escaped parentheses \( \); if you look at the phrase we were looking for, the "anything except for opening angle bracket <" section is indeed surrounded by escaped parentheses. The way you insert this part of the search phrase into the replacement phrase is with an escaped number. Thus, the expression \1 in the replacement phrase <em>\1</em> inserts from the search phrase the first occurrence that was found and surrounded by escaped parentheses. In our example we have just one saved phrase, so it's replacement expression is \1. If we had had three found and saved expressions, their expression would have been \1, \2 and \3, respectively.
That's it for the commands for searching and replacing <span></span> defined italics with simple <em></em> tags! If you've been able to follow the logic, you can do lots of other things already, as the most important expressions for searching and replacing text intelligently are indeed what we have been dealing with here:
1. finding "one or more" numbers with [0-9][0-9]*
2. finding "one or more of anything except x" with [^x][^x]*
3. saving what you find by surrounding it with escaped parentheses \( \)
4. inserting what you found and saved into the replacement phrase with \1, \2, \3 etc.
Here's a few others, which will probably be pretty clear if you've already understood how the ones above work:
5. Finding "one or more letters" is similar to finding one or more numbers: [A-Za-z][A-Za-z]* will find one or more upper or lower case letters; use [aeiou][aeiou]* to find one or more vowels.
6. Want to find "either this or that" character? Use Jo[a|h]n to find all occurrences of Joan and John".
If you've understood all or even most of the above, the following leftovers from the example sed script file will be a lot easier.
# change all non-breaking spaces to normal spaces
s| | |g
Change all non-breaking spaces into normal spaces.
# remove various anchors, breaks and images
s|<a[^>][^>]*>||g
s|</a>||g
s|<br[^>][^>]*>||g
s|<img[^>][^>]*>||g
s| | |g
# delete all p styles and change them to default p style
s|<p[^>][^>]*>|<p>|g
s|<p>|<p class="fst">|g
The commands in the first section remove all <a></a> tags (1st and 2nd command), all line breaks (3rd command), all links to images (4th command), and all tabs are changed into a single space (5th command). (ABBYY Finereader doesn't produce consistent footnote links, i.e. not without dropping one here or there which messes up the numbering, so they're better done by hand during proof-reading, and for that a clean slate is best.)
The commands in the second section change all <p style="whatever"> tag definitions into plain <p> tags without any inline definitions, and then change all plain <p> tags in into one of the standard MIA <p> tag definitions.
To finish up this tutorial, here's a number of examples of what you can do with regex, without going into the logic of how the examples work. This is just to show further what you can do with regex if you're doing HTML markup for MIA. The examples are given in the regex dialect that sed understands.
If you have a plain text file without any markup, you can define (almost) every line of text (but not empty lines) with <p></p> tags with two commands:
s|^[A-Za-z0-9][A-Za-z0-9]*|<p class="fst">&|
s|[.,:;a-z][.,:;a-z]*$|&</p>|
If you have a plain text file, where the footnote references have been marked simply with numbers in square brackets[1], but without any link markup, here's how you can make the link markup for all footnotes (given that their notation is consistent) with two commands. This could be handy if you have received a plain text file with lots of this kind of footnotes from a volunteer who is not literate in HTML. You have naturally advised them beforehand to mark the footnote references in the body of the text with [1r], [2r], [3r] etc. (where "r" stands for "reference"), and at the bottom of the page the actual footnotes with [1f], [2f], [3f] etc. (where "f" stands for "footnote"). The first command is for the footnote references in the body of the text, the second one for the actual footnotes at the bottom of the page.
s|\[\([0-9][0-9]*\)r\]|<a class="footnotes" id="footnoteref\1" href="#footnote\1">[\1]</a>|g
s|\[\([0-9][0-9]*\)f\]|<a class="footnotes" id="footnote\1" href="#footnoteref\1">[\1]</a>|g
If you have a plain text file where there is no empty lines between paragraphs (which is harder to read), you can add an extra line between the paragraphs with a single command:
s|^..*|&\r
If the text is already marked up, you could use:
s|</p>$|&\r
Further reading
Here's some links to materials on the net on regular expressions, in case you want to dig deeper.
Learning regular expressions (from stackoverflow.com)
Regular Expressions Basics! (at ryanstutorials.net)
Regex Tutorials (at regextutorials.com)
Regular Expressions (at grymoire.com)
Sed - An Introduction and Tutorial (at grymoire.com)
Regular Expressions Tutorial (at regular-expressions.info)
Regex Reference (at regexstorm.net)
Appendix
Some differences between the regex dialects in gedit and sed
First of all, this section doesn't cover all the differences between the regex dialects of gedit and sed. It covers the differences only to the extent that is relevant for the examples in this tutorial. So the scope is very limited. This is just a quick reference for anyone using the tutorial.
1. To save a found phrase, gedit needs unescaped parentheses ( ) around the found phrase you want to save, while escaped parentheses \( \) denote "literal" parentheses one would use in normal text (like this). In sed the notation is the opposite: escaped parentheses for saving, unescaped ones for "literal" use.
2. All examples in this tutorial use the expression [0-9][0-9]* to find "one or more numbers". To achieve the same effect, gedit understands also the notation [0-9]+ by default; sed doesn't. It is easier to write the latter, shorter version, but for the sake of making a complex topic that is already too hard as simple as possible for the beginner, the tutorial has stuck to the longer version everywhere, because it works for both gedit and sed, and thus causes less confusion (the "zero or more" issue connected to the longer version is left on the side here...). But now you know you have a shortcut in gedit if you want to use it. (And while you're at it, why not simply use \d+ to find one or more of any number!)
Notes:
[1] In general, looking for characters inside square brackets will try to match as many characters as possible. Thus, looking for [word] will match a single w, o, r or d, as well as wwwooorrrddd or wordwordwordwdorwroododddorrowowow.
[2] Offhand "zero or more" might seem like nonsense, but it does have a useful function. If you wanted to find all lines with the phrase "This line" and change all of these lines into just "It's a match!", you could search for .*This line.*. (The dot . is another special character which stands for "any character except a line break". So if you want to find a literal dot, you should escape it with the backslash.) The search phrase part .* will match zero or more of any character (except a line break). However, as these zero or more of any characters have to be around the phrase "This line", the search phrase will find both those lines where there's nothing else but "This line" (zero characters around it) as well as those lines with whatever written around the phrase, such as "asdfasdfasdfThis lineasdfadf" or " This line fdaa fff d ddd".
[3] On this line the difference between gedit and sed regex becomes apparent! In gedit unescaped parentheses were used to saving search phrase sections and escaped one were literal parentheses, but in sed this is reversed! In sed unescaped parentheses are literal parentheses, while escaped ones are used for saving.
Contact the Marxists Internet Archive Admin Committee for further information